MoeASR技术报告
MoeASR 技术报告
0. 概述
MoeASR 是一套面向困难日语长音频字幕场景的工程化 ASR 系统。它不追求“单模型一次识别就结束”的理想路径,而是把多阶段流水线、风险驱动重试、对齐容灾和可审计产物组织成一个完整闭环。
说得更直接一点,我要解决的不是“能不能出字”,而是“面对长音频、脏音频和困难样本时,系统还能不能稳定地交付一份可播放、可复盘的 SRT 字幕”。
1. 项目定位
1.1 项目要解决什么问题
传统 ASR Demo 往往只覆盖“干净音频 + 单模型 + 单次推理”的 happy path,但真实字幕交付场景里,麻烦通常都出在下面这些地方:
- 长音频切分不稳定,一旦切坏,整段识别质量就会被拖下来。
- 强制对齐在困难样本上很容易出现时间戳坍塌、零时长字符簇和时间逆跳。
- 单一模型很难覆盖不同音频条件,模型切换和策略切换成本也比较高。
- 失败案例很难复盘,缺少结构化调试产物和稳定的回归验证抓手。
所以,MoeASR 的核心目标从来不是“再写一个语音识别脚本”,而是搭一条可以持续优化的字幕生产流水线:
- 输入是原始音频。
- 输出是可播放、可交付的 SRT 字幕。
- 中间过程可诊断、可回退、可比较、可批量评测。
1.2 技术栈
- 推理与音频处理:PyTorch、Torchaudio、Librosa
- ASR 引擎:faster-whisper、Transformers Whisper、FunASR、Qwen3-ASR
- 对齐引擎:Qwen Forced Alignment、ESPnet、CTC Segmentation
- 语言学辅助:fugashi / unidic-lite
- 交互与批处理:Gradio、批处理调度脚本、NVML GPU 门控
2. 系统总览
2.1 设计原则
这个项目的架构不是“一个大模型外面套几层脚本”,而是比较典型的编排层和能力层分离:
- 入口层:
main.py、webui.py、flux_asr/batch.py - 编排层:
FluxASRPipeline - 能力层:VAD、ASR、Aligner、Cleaner、Fusion、Export
- 适配层:
UniversalVADAdapter、UniversalASRAdapter、UniversalAlignerAdapter - 产物层:
run_artifacts.py统一管理输出路径、运行清单和调试文件
这样拆的好处很明确:主流程只负责“什么时候调用什么”,复杂策略尽量下沉到 stage 和 adapter 里,避免主控制器一步步膨胀成不可维护的巨型函数。
2.2 主数据流
8 阶段数据流图
Audio -> Stage0 预处理 -> Stage1 VAD -> Stage2 ASR -> Stage3 清洗 -> Stage4 对齐 -> Stage5 融合与重试 -> Stage6 后处理 -> Stage7 SRT 导出
整条流水线的主线如下:
- Stage 0:音频标准化与缓存
- Stage 1:VAD 检测语音区间
- Stage 2:ASR 转写与低质量片段重试
- Stage 3:文本清洗与结构化统计
- Stage 4:字符级对齐、风险评估与容灾回退
- Stage 5:VAD 与字符时间戳融合,必要时做异常时间轴重建
- Stage 6:可选 LLM 润色 + Timeline Hardener
- Stage 7:SRT 导出与最终安全修复
3. 核心架构拆解
3.1 统一接口与多模型适配层
项目一开始就没有把自己绑死在单一模型上,而是先定义稳定接口,再通过 Adapter 去接不同的能力源:
1 | class VADInterface(ABC): |
这层抽象带来的收益主要有三点:
- 主流程不需要改动,就可以切换 Whisper、FunASR、Qwen3-ASR 等不同 ASR 引擎。
- 可以用 Qwen、ESPnet、CTC 三种对齐方案去覆盖不同模型格式和资源条件。
- “模型目录长什么样”“推理后端输出什么格式”这类兼容问题,都能尽量收敛到适配层里处理。
技术取舍
- 选择多适配器而不是单模型直调,确实会带来额外的抽象复杂度和适配成本。
- 但换来的好处是更高的实验效率、更快的模型接入速度,以及失败场景下更强的可回退能力。
这本质上就是典型的工程化折中:牺牲一部分局部简洁性,换取整体的可扩展性和可维护性。
3.2 Stage 2:分块识别与自治重试
Stage 2 是整条链路里第一个明显的复杂度高点。这里真正要解决的问题不是“怎么转写”,而是“什么时候应该怀疑当前结果不可信,以及怎么重试才不会把错误继续放大”。
关键机制
- 先用 VAD 切出语音片段,再做动态合并,控制单次识别窗口。
- 对超长单段,基于短时能量在低能量点切分,尽量避免在语音中间硬切。
- 用
evaluate_asr_quality()评估片段质量,核心特征包括:- 字符密度是否异常
- 是否出现长重复子串
- 字符多样性是否异常偏低
- 根据片段形态选择不同的重试路径:
- 多 VAD 片段低质量 -> 按原始 VAD 子段回退
- 单长段低质量 -> 递归二分重试
- 所有重试结果统一进入仲裁器,只有在“质量提升足够明显”且“文本增量没有失控”时,才替换原结果。
为什么这样设计
ASR 系统里最危险的情况,其实不是“没有结果”,而是“给了一段看起来像样、实际上质量很差的文本”。如果重试策略没有止损边界,错误就很容易从片段级放大成全局级问题。
所以这里的重点不在“尽量多重试”,而在“有条件地重试、严格地验收”。
伪代码
1 | for chunk in audio_chunks: |
Stage 2 重试状态机
Initial ASR -> Quality Eval ->
none/vad_segments/binary_split-> Arbitration -> Selected Result
技术取舍
- 激进重试确实可能拉高一部分困难片段的上限,但也更容易引入幻觉扩写。
- 当前方案选择“保守验收”,宁可保留原结果,也不接受收益不明确的重试输出。
这其实就是精度和稳定性的取舍,而这个项目更偏向生产可控性。
3.3 Stage 4/5:对齐容灾与时间轴重建
真实问题往往不在“能不能对齐”,而在“对齐崩了之后,系统还能不能把结果交付出来”。
问题背景
字符级强制对齐在困难音频上,经常会出现下面这些异常:
- 大量字符被压缩进极短时间窗
- 连续字符出现零时长
- 时间戳不单调
- 单个字符时长异常拉长
如果不做容灾,最后就会出现一种很糟糕的情况:文本可能没错,但时间轴已经不可播放,最终还是没法交付。
解决方案
MoeASR 在这里做了四层防线:
-
对齐异常标记
对时长异常字符和零时长幻觉簇做降权,避免污染后续融合。 -
Alignment Sentinel
用覆盖率、聚合 CPS、零时长比、退化比、单调性等指标判断是否发生“时间戳坍塌”。 -
分级回退
只在严重坍塌时触发回退,顺序为:- 插值修复
- 基于 VAD 的字符重新分布
-
Timeline Hardener
对融合后的字幕做单调性硬化,修复重叠、倒退、零长度和非法时间。
伪代码
1 | assessment = sentinel.assess(aligned_chars) |
Alignment Fallback 决策
Aligner Output -> Sentinel Assess -> Mild Collapse / Severe Collapse -> Interpolation -> VAD Redistribution -> Fusion
为什么不是“失败就报错”
因为字幕系统追求的不是“理论上最完美的时间戳”,而是“在困难样本下尽量给出一份还能正常播放的结果”。
这里的核心取舍是:
- 保留对齐精度:优先使用原始 aligner 结果
- 保证交付稳定:对严重异常做结构化退化,而不是让整条链路直接失败
换句话说,这里追求的是“优雅降级”,不是“非黑即白”。
3.4 文本清洗不是正则补丁,而是阶段化处理
很多 ASR 项目会把文本清洗写成一串零散的正则替换,后面基本很难继续分析。MoeASR 则把清洗显式做成了阶段式流水线:
regex_repetitionchar_floodfiller_densityhallucination_blacklistwhitespace
每个阶段都会输出:
- 是否开启
- 命中次数
- 删除字符数
- 耗时
这样做带来两个很直接的价值:
- 可以量化“到底是哪一个清洗阶段真正起了作用”
- 可以按场景定制 profile,而不是把所有规则永远全开
技术取舍
- 规则越多,误杀风险越高。
- 当前方案通过 profile 和开关控制,把强规则限制在需要的场景里,而不是默认全局启用。
这是一种可解释性优先的设计思路,而不是黑盒式后处理。
3.5 产物治理与可审计能力
MoeASR 的运行产物按 run_id 隔离,整体结构如下:
single/:单文件输出batch/:批处理输出artifacts/:中间调试文件run_manifest.json:输入、输出、配置快照、风险明细、清洗统计、导出修复统计
这套设计主要解决了三个实际问题:
- 不同实验之间不会互相覆盖
- 出问题时可以定位到具体运行配置
- 批处理和模型对比能够沉淀成可复用的数据资产
技术取舍
- 额外写入调试产物会增加一定 I/O 开销。
- 但对复杂流水线来说,可审计性带来的收益远远高于这点成本。
对于需要持续迭代的模型系统,这种能力不是“附加项”,而更像是地基。
3.6 WebUI 与批处理的工程边界
这个项目没有刻意追求表面上的高并发,而是明确选择了“受控串行”:
- WebUI
concurrency_limit=1 - 批处理前做 GPU 利用率和空闲显存检查
- 通过单例 Pipeline +
update_config()热更新模型与参数
原因也很直接:
- 桌面 GPU 场景下,多请求并发最容易引发显存抖动和模型热切换冲突
- 单例 Pipeline 可以复用模型,降低加载成本
- GPU 门控可以减少任务雪崩和长时间卡死
技术取舍
- 放弃了名义上的吞吐并发能力。
- 换来了更稳定的显存行为和更高的实验可复现性。
对这个项目的目标用户来说,这个取舍是合理的,因为真正的瓶颈主要在 GPU 资源,而不是 Web 请求数。
4. Benchmark 与结果解读
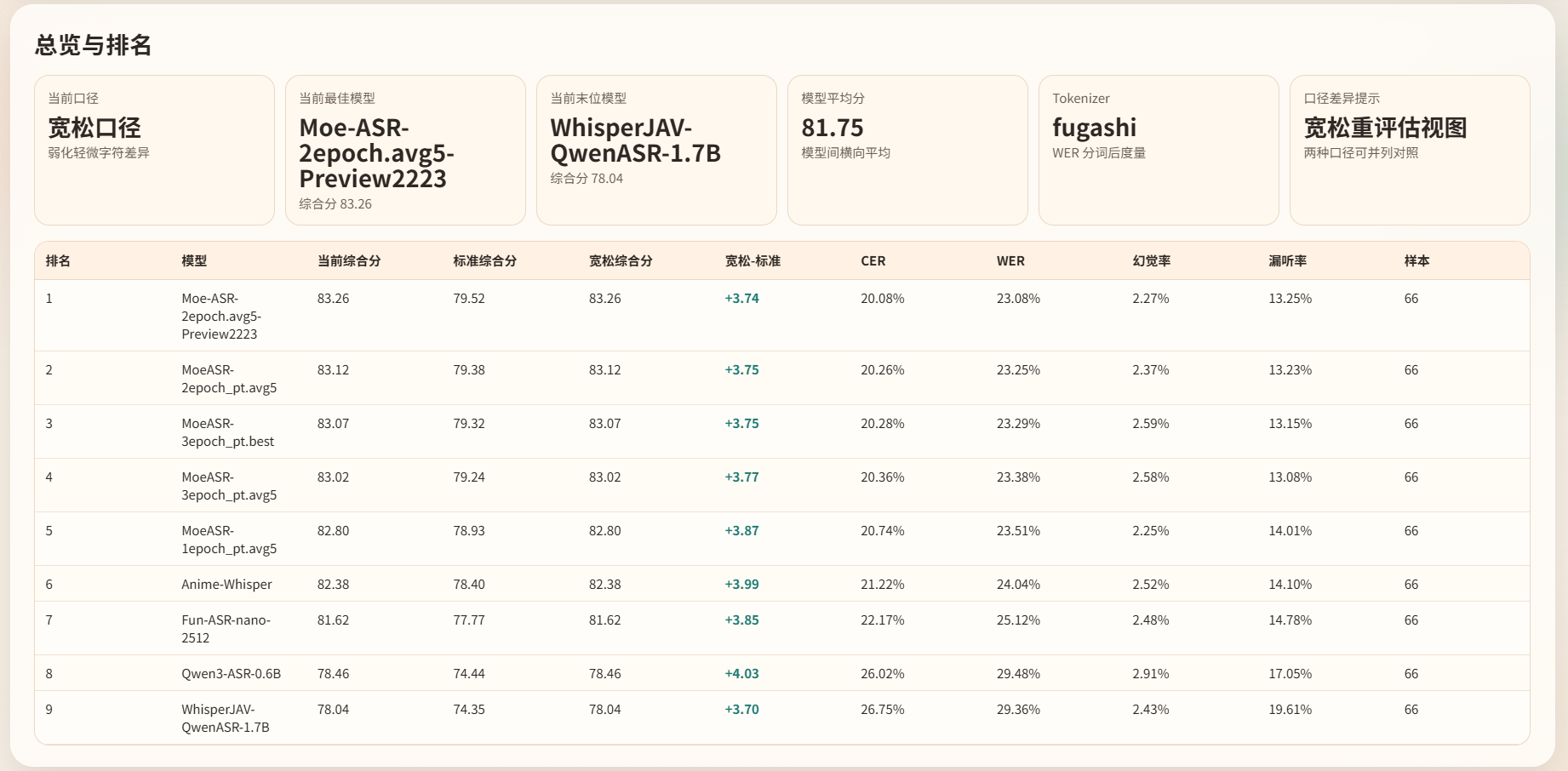
4.1 评测口径
report/data/deep_report_data.js 中的综合分定义为:
1 | Composite Accuracy = 100 * (1 - (0.4 * CER + 0.3 * WER + 0.2 * HallucinationRate + 0.1 * MissRate)) |
相比只看 CER,这个指标更接近真实交付质量,因为它同时考虑了:
- 文本错误率
- 幻觉率
- 漏字率
4.2 原始评测集结果
基于 report/data/metrics_per_model.csv,在 66 个样本组成的评测集上,结果如下:
| 模型 | Composite Accuracy | CER | WER |
|---|---|---|---|
| Moe-ASR Preview | 79.52 | 0.2501 | 0.2777 |
| MoeASR-2epoch_pt.avg5 | 79.38 | 0.2517 | 0.2798 |
| MoeASR-3epoch_pt.best | 79.32 | 0.2515 | 0.2805 |
| Anime-Whisper | 78.40 | 0.2640 | 0.2916 |
| Fun-ASR-nano-2512 | 77.77 | 0.2725 | 0.2991 |
| Qwen3-ASR-0.6B | 74.44 | 0.3175 | 0.3396 |
从这组结果里可以直接看到:
Moe-ASR Preview在原始评测集上排名第一,MoeASR-2epoch_pt.avg5和MoeASR-3epoch_pt.best紧随其后。- 相比
Anime-Whisper,Preview 版本的 Composite Accuracy 提升了 1.12 分,CER 和 WER 都下降了约 0.0138。 - 相比
Qwen3-ASR-0.6B,Preview 版本的 Composite Accuracy 提升了 5.08 分,CER 下降 0.0674,WER 下降 0.0619。
4.3 去噪评测集结果
基于 report/data/metrics_per_model_denoised.csv:
- 当前最佳版本的 Composite Accuracy 为 77.58
- Preview 版本的 Composite Accuracy 为 77.16,排名第 5
- 与当前最佳相比,仍有约 0.42 分差距
这说明新架构在原始音频主链路上已经证明有效,但和去噪前处理结合后,还没有把优势稳定保留下来。
这一点我觉得很值得明确写进复盘里,因为它反映的不是“结果不好看”,而是我对系统边界的判断:
- 新架构不是“全面碾压”,而是先在主路径上证明收益
- 去噪链路里的分布偏移和策略耦合,仍然需要专项调参
4.4 困难度分布
基于 report/data/metrics_per_work.csv 的作品级汇总:
- 最容易和最困难样本之间的综合分跨度达到 42.21 分
- CER 跨度从 0.1038 到 0.6224
- WER 跨度从 0.1090 到 0.6624
这意味着这个项目并不是在一组同质数据上刷平均分,而是在一个明显存在难度分层的样本集上做工程优化。
5. 当前局限性与未来优化方向
5.1 去噪链路上的收益还不稳定
Preview 架构在原始评测集上表现最好,但在去噪集上还不是最优。这说明前处理和后续对齐、清洗策略之间依然存在耦合,后面还需要继续做解耦,并重新标定相关阈值。
5.2 Stage 2 和 Fusion 仍然是复杂度热点
_stage2_asr()、FusionMatcher.fuse() 目前承担了比较多的策略逻辑。虽然已经通过 stage 函数拆分掉了一部分复杂度,但继续做职责下沉,依旧很有价值。
5.3 自动策略路由仍有经验成分
批处理现在已经支持多策略变体和自动路由,但部分规则仍然依赖经验阈值。下一步可以把路由特征显式化,甚至引入轻量质量预测器,进一步减少人工调参。
ArisuMika
关注Arisu喵!关注Arisu谢谢喵!