AI Avatar 多智能体交互系统技术报告
AI Avatar 多智能体交互系统技术报告
1. 项目概述
这是一个面向游戏角色交互的集中式多智能体调度系统。UE5 负责采集场景内角色状态、发送结构化请求并执行动作;Python / FastAPI 负责协议校验、LLM Function Calling 调度、动作归一化和几何换算;LLM 本身只负责理解语义、拆解任务、选择角色,再生成动作调用。
说到底,我想解决的并不是“让 AI 能说话”这么简单,而是“怎么把一条自然语言指令,稳定地变成游戏世界里多个角色的可执行动作”。
这个项目要解决的核心问题主要有三个:
- 单轮自然语言指令需要同时调度多个场景角色,传统单 Agent 对话链路很难稳定覆盖。
- LLM 直接生成 UE5 世界坐标时很容易出现空间幻觉,尤其是“向前走 15 米”“跟着她一起走”这类相对位移任务,稳定性会明显下降。
- UE5 侧需要一条可验证、可扩展、后续还能平滑迁移到 C++ 原生模块的消息协议和执行链路,而不是继续依赖自由文本解析。
技术栈:Unreal Engine 5、C++、Blueprint、Python、FastAPI、Pydantic v2、LLM Function Calling
2. 我想把它做成什么
如果用一句话来概括,我想做的是把 LLM 从“直接控制游戏世界”的不稳定执行者,降成一个只做意图理解和动作规划的调度器;真正和游戏世界强耦合的状态、坐标、实体路由、协议校验,都应该收回到后端和引擎侧。
这套设计对应的工程目标是:
- 单次请求下支持多角色批量调度。
- 将角色状态序列化为结构化上下文,而不是拼接自然语言描述。
- 用严格协议替代自由 JSON,确保 UE5 可以稳定映射动作。
- 将空间数学从 LLM 中剥离,避免“看起来合理、实际上错位”的位移结果。
- 让 Blueprint 原型可以平滑下沉为 UE5 C++ Subsystem / Router 核心。
3. 系统架构
3.1 模块分层
| 层级 | 模块 | 责任 | 当前落地 |
|---|---|---|---|
| Engine UI 层 | WBP_AIChatPanel |
采集输入、遍历场景角色、组装请求、接收响应 | Blueprint |
| Engine Routing 层 | ReceiveAICommand / Command Router |
按 agent_id + action_code 路由动作到实体 |
Blueprint 原型,目标迁移到 C++ |
| Engine Execution 层 | BP_AIAgent |
执行 MoveTo 等具体行为 |
Blueprint |
| Orchestrator 层 | FastAPI /chat |
协议校验、调度 LLM、执行工具、归一化动作 | Python |
| Agent Registry 层 | GameMaster / AgentProfile / BaseTool |
角色人设、能力集合、动态工具 schema | Python |
| Reasoning 层 | 兼容 OpenAI 接口的 LLM | 意图理解、角色选择、工具调用、回复生成 | 外部模型 |
3.2 为什么我选集中式而不是分布式
我没有采用“每个角色一个 Agent,自主互相对话”的分布式架构,而是先选择了集中式调度器,原因很直接:
- 场景真值只在 UE5 里最可靠,集中式架构更容易把“当前有哪些角色、每个角色的坐标和朝向是什么”一次性送进上下文。
- 多角色协同时,单个调度器更容易保证任务分配一致,避免两个 Agent 对同一角色重复下指令。
- Function Calling 天然更适合“由一个决策器产出多个结构化动作”这种场景。
当然,这样做也有很明确的取舍:
- 好处是协议清晰、调试成本低、整体可控性更强。
- 代价是中央调度器会成为单点瓶颈,后续必须补上缓存、超时控制和并发治理。
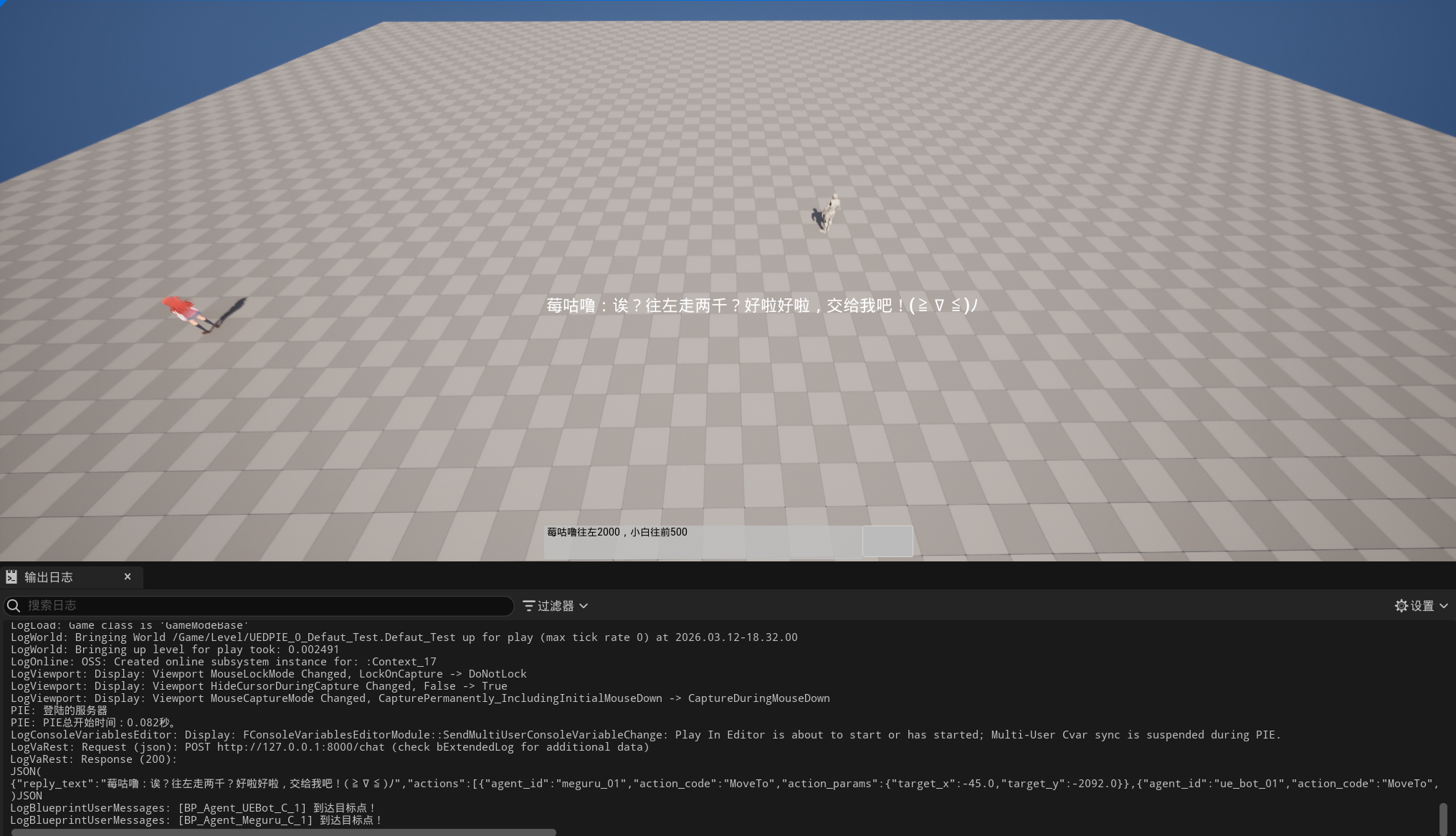
4. 端到端执行链路
4.1 请求阶段
- 玩家在
WBP_AIChatPanel输入自然语言。 - 点击发送后,Widget 遍历场景内全部
BP_AIAgent,采集agent_id / agent_x / agent_y / agent_yaw。 - Widget 将
user_text + agents_state[]组装成ChatRequest,通过 VaRest 发送给 FastAPI/chat。
4.2 调度阶段
- FastAPI 使用 Pydantic 严格校验请求协议。
GameMaster根据当前激活角色动态构建 prompt 和 tool schema。- LLM 通过 Function Calling 生成一个或多个工具调用。
- 后端逐个执行工具,并把结果归一化成 UE5 可执行的
actions[]。
4.3 执行阶段
- UE5 收到
ChatResponse后,读取reply_text作为角色回应。 - Widget 遍历
actions[],按agent_id找到目标 Actor。 - 找到目标后调用
ReceiveAICommand(action_code, target_x, target_y)。 BP_AIAgent依据action_code进入对应执行分支,当前已经验证MoveTo -> AIMoveTo这条链路。
这条链路里最关键的一点是:从头到尾,LLM 都没有直接接触 UE5 Actor,也没有直接控制世界状态;它输出的只是一个经过协议约束的“动作意图”。
5. 协议设计:为什么我要用严格结构化协议
5.1 请求协议
后端使用 Pydantic 定义了严格请求结构:
1 | { |
对应实现:
AgentState / ChatRequest / ActionItem / ChatResponse使用extra="forbid"禁止脏字段进入系统。ChatResponse.actions[]采用action_code + action_params的二层结构,避免把所有动作揉成一个超大 JSON。
代码锚点:
- 协议模型:
mock_server.py:17-61 - 请求入口:
mock_server.py:461-469
5.2 工具 schema
工具 schema 由 BaseTool 统一生成,并强制注入 agent_id:
1 | { |
这一步的意义不是“给 LLM 看一份说明书”,而是把“谁来执行动作”提升成协议级强约束,避免多角色场景里最常见的串指令问题。
代码锚点:
agent_core.py:18-41agent_core.py:45-134
6. 语义 - 数学解耦:核心稳定性设计
这是整个项目里最关键的工程决策之一。
6.1 问题
LLM 很擅长理解“向前走 10 米”“跟她一起向右移动”这种自然语言,但它并不擅长稳定地做 UE5 坐标系下的几何换算。直接让模型输出绝对坐标,常见问题主要有:
- 单位混乱,米和厘米混用。
- 忽略角色当前朝向,导致“向前”被错误理解成世界坐标轴上的固定方向。
- 在跟随类动作里,把参考角色和执行角色搞混。
6.2 方案
我把动作拆成了两层:
- 语义层:LLM 只输出
MoveRelative(forward, right)或MoveWithAgent(reference_agent_id, forward, right)。 - 数学层:后端读取 UE5 上传的当前状态,在服务端完成 yaw 旋转、坐标换算和目标点落地,最后再统一归一化成
MoveTo(target_x, target_y)。
换算逻辑如下:
1 | dx = forward * cos(yaw) - right * sin(yaw) |
代码锚点:
execute_move_relative:mock_server.py:222-258execute_move_with_agent:mock_server.py:261-300- 工具分发入口:
mock_server.py:303-387
6.3 结果
这一步把空间计算从“概率性输出”变成了“确定性函数”,本质上就是把大模型从控制环里拿掉,改成一个“自然语言编译器”。
在我看来,这也是整个项目里最能体现设计思路的一块。因为它不是单纯换了个 prompt,而是明确划清了大模型应该做什么、不应该做什么。
7. 集中式多智能体调度:为什么单次请求能指挥多角色
GameMaster 维护了一份角色名册,每个角色都会绑定:
agent_id- 角色设定
- 可用工具列表
后端会根据当前场景里真正存在的角色,动态裁剪暴露给 LLM 的工具集合,而不是把所有能力一股脑丢给模型。
例如:
ue_bot_01只能移动。meguru_01除了移动,还具备PlayEmote。
这种设计有两个很直接的好处:
- 减少模型误调用不存在能力的概率。
- 把“角色能力边界”从 prompt 文本,提升成代码级约束。
代码锚点:
- 角色与工具注册:
agent_core.py:168-195 - 动态工具裁剪:
agent_core.py:197-208 - 动态指挥 prompt:
agent_core.py:210-255
7.1 为什么 prompt 里会有大量硬约束
这不是“提示词工程炫技”,而是在给 LLM 建立一份执行规约:
- 能调用工具时就不要空谈。
- 多角色场景下必须精确填写
agent_id。 - 相对移动严禁模型自己去算绝对坐标。
- 回复文本只允许输出角色台词,不能把推理过程带回前台。
我还在后端补了一个 sanitize_reply_text,专门清洗 <think> 之类的模型污染输出,算是再加一层保险。
代码锚点:
- Prompt 约束:
agent_core.py:235-255 - 回复清洗:
mock_server.py:175-185
8. UE5 侧原型链路:Blueprint 已经验证了什么
根据当前 Blueprint 导出内容,UE5 侧已经验证了下面四件事:
8.1 状态采集闭环
WBP_AIChatPanel 点击发送后会:
GetAllActorsOfClass(BP_AIAgent)- 读取每个角色的
AgentID - 读取位置
K2_GetActorLocation - 读取朝向
K2_GetActorRotation - 组装成
agents_state[]
这一步说明“世界状态上送”不是停留在概念层,而是真的已经跑通了。
8.2 请求构造闭环
Widget 使用 VaRest 构造 POST 请求,将:
user_textagents_state[]
发往后端 ServerURL。
这时候其实已经形成了最小可用的人机交互入口。
8.3 动作路由闭环
收到响应后,Widget 会:
- 读取
reply_text - 读取
actions[] - 遍历动作数组
- 解析
agent_id / action_code / action_params - 在场景内二次遍历
BP_AIAgent - 找到匹配
AgentID的实体并调用ReceiveAICommand
这一步说明消息解析、指令路由和执行链路已经不是写在设计图上的东西,而是真的联调通了。
8.4 实体执行闭环
BP_AIAgent.ReceiveAICommand 当前已经实现:
- 按
ActionCode做字符串分发。 MoveTo分支将TargetX / TargetY组装为目标点。- 保留当前 Z 值,调用
AIMoveTo。
虽然现在执行器仍然是 Blueprint,但接口边界已经很接近 C++ 原生化:输入是结构化命令,输出是行为执行结果,而不是一堆散乱蓝图节点互相直连。
9. 从 Blueprint 原型到 C++ 核心:我会怎么下沉
现阶段的原型已经验证了协议、路由和行为执行链路。下一步真正需要下沉到 C++ 的,不是 UI,而是下面这三个核心模块:
UAICommandRouterSubsystemFAIActionCommand结构体- 异步命令队列 + 状态映射层
建议的 C++ 抽象如下:
1 | USTRUCT(BlueprintType) |
这样拆的好处很明确:
- Widget 只负责 UI,不再承担复杂 JSON 解析。
- Actor 只负责执行,不再承担路由职责。
- 命令分发、重试、超时和队列调度都可以下沉到 Subsystem 统一处理。
10. 关键技术取舍
10.1 Function Calling vs 自由 JSON
我选择 Function Calling,而不是让模型裸输出 JSON 文本。
原因:
- schema 更稳定,字段约束更强。
- 多角色场景里更容易校验
agent_id和参数完整性。 - 可以把“语义规划”和“动作执行反馈”组织成一个比较稳定的工具调用闭环。
代价:
- 需要维护 tool schema。
- 新增动作时要同时更新工具定义和 UE5 路由层。
10.2 中央调度器 vs 每角色自治
我选择中央调度器,是因为现阶段的主要痛点不是“角色人格自治”,而是“多角色任务怎么稳定执行”。
收益:
- 世界状态更一致。
- 更容易做多角色协作。
- 整个系统的边界也更容易讲清楚。
代价:
- 横向扩展压力会集中在后端。
- 调度器的 prompt 复杂度会上升。
10.3 Blueprint 快速验证 vs C++ 一次到位
我先用 Blueprint 验证链路,而不是一开始就全量写 C++。
原因:
- 这个项目的高风险点在协议和调度逻辑,不在 UI 节点本身。
- Blueprint 更适合快速打通 UE5 <-> HTTP <-> Actor 的最小闭环。
- 等协议和动作模型稳定下来,再做 C++ 核心化,返工成本会更低。
代价也很明显:
- Blueprint 解析复杂 JSON 的可维护性比较差。
- 命令队列、重试和并发控制很难做得优雅。
- 一旦行为扩展多起来,蓝图会迅速膨胀。
11. 代码索引
| 能力点 | 代码位置 |
|---|---|
工具 schema 强制注入 agent_id |
agent_core.py:18-41 |
| MoveTo / MoveRelative / MoveWithAgent / PlayEmote | agent_core.py:45-134 |
| 角色名册与能力边界 | agent_core.py:168-195 |
| 动态 prompt 与执行铁律 | agent_core.py:210-255 |
| 严格协议模型 | mock_server.py:17-61 |
| 兼容 OpenAI 接口的客户端 | mock_server.py:101-150 |
| 回复污染清洗 | mock_server.py:175-185 |
| 相对坐标 -> 绝对坐标换算 | mock_server.py:222-300 |
| 工具调用解析与动作归一化 | mock_server.py:303-387 |
| LLM 工具调用循环 | mock_server.py:399-458 |
FastAPI /chat 接口 |
mock_server.py:461-469 |
12. 当前局限性与未来优化方向
这部分我想单独说一下,因为复盘不能只写做成了什么,也得把还没做完的地方讲清楚。
12.1 当前局限性
- UE5 侧路由和执行器目前仍以 Blueprint 原型为主,C++ 原生命令核心还没有完全落地。
- 引擎侧还没有真正的命令队列、超时重试、取消执行和状态回写闭环。
- 当前 Actor 执行链路主要验证了
MoveTo,更多动作类型还需要继续补齐执行器。 - HTTP 客户端目前使用
urllib,还没有做连接复用、流式输出和更细粒度的错误分层。 - 缺少自动化协议测试、回放测试和端到端压测数据。
12.2 下一步计划
- 将
WBP_AIChatPanel中的 JSON 解析与动作路由下沉到UGameInstanceSubsystem。 - 用
FAIActionCommand统一动作载体,替换蓝图里的临时字段拼装。 - 引入异步命令队列和状态机,支持执行中、成功、失败、重试等生命周期。
- 为
PlayEmote、交互、跟随、打断等行为补齐 UE5 原生执行器。 - 增加契约测试与延迟监控,让这套系统从 Demo 链路继续往可长期维护的交互框架走。
ArisuMika
关注Arisu喵!关注Arisu谢谢喵!